随着数据技术的快速发展,了解并掌握各种工具和技术变得尤为重要。为此,我们准备在Apache SeaTunnel社区发起如何使用连接器的Demo演示计划,邀请所有热爱数据同步技术的同学分享他们的知识和实操经验!
本期我们邀请到了社区PMC高俊老师,参与录制的主题是:如何从MySQL同步到Doris,如果您对此计划感兴趣,也欢迎联系社区运营同学参与Demo录制!无论您是数据工程师、开发者还是技术爱好者,都欢迎您参与并展示您的技术才能。
敲重点敲重点如果你是用户,想看什么同步场景的Demo!请下滑到最底部留言,我们优先出品呼声最高的同步场景Demo!
Demo计划目标
我们的目标是创建一个共享和学习的平台,通过具体的Demo演示和对应的文档帮助社区成员更好地理解和应用各种数据连接器。这些Demo可以帮助新手快速学习,同时也为资深专家提供一个展示创新解决方案的舞台。
MySQL同步到Doris
src="//player.bilibili.com/player.html?aid=1503234572&bvid=BV1dD421n7YU&cid=1507007688&p=1" scrolling="no" border="0" frameborder="no" framespacing="0" allowfullscreen="true">JDBC MySQL连接器
描述
通过JDBC读取外部数据源数据。
支持的MySQL版本
- 5.5/5.6/5.7/8.0
支持的引擎
Spark
Flink
SeaTunnel Zeta
使用依赖
Spark/Flink引擎
- 您需要确保jdbc驱动jar包已放在
${SEATUNNEL_HOME}/plugins/目录下。
SeaTunnel Zeta引擎
- 您需要确保jdbc驱动jar包已放在
${SEATUNNEL_HOME}/lib/目录下。
MySQL 连接器关键特性
- 批处理
- 流处理
- 精确一次
- 列投影
- 并行处理
- 支持用户自定义分片
- 支持多表读取
支持查询SQL并可实现投影效果。
支持的数据源信息
| 数据源 | 支持的版本 | 驱动 | URL | Maven下载 |
|---|---|---|---|---|
| MySQL | 不同的依赖版本有不同的驱动类。 | com.mysql.cj.jdbc.Driver | jdbc:mysql://localhost:3306:3306/test | 下载 |
数据库依赖
请下载与'Maven'对应的支持列表,并复制到'$SEATNUNNEL_HOME/plugins/jdbc/lib/'工作目录
例如MySQL数据源:cp mysql-connector-java-xxx.jar $SEATNUNNEL_HOME/plugins/jdbc/lib/
数据类型映射
| MySQL数据类型 | SeaTunnel数据类型 |
|---|---|
| BIT(1) INT UNSIGNED | BOOLEAN |
| TINYINT TINYINT UNSIGNED SMALLINT SMALLINT UNSIGNED MEDIUMINT MEDIUMINT UNSIGNED INT INTEGER YEAR | INT |
| INT UNSIGNED INTEGER UNSIGNED BIGINT | BIGINT |
| BIGINT UNSIGNED | DECIMAL(20,0) |
| DECIMAL(x,y)(获取指定列的指定列大小.<38) | DECIMAL(x,y) |
| DECIMAL(x,y)(获取指定列的指定列大小.>38) | DECIMAL(38,18) |
| DECIMAL UNSIGNED | DECIMAL(获取指定列的指定列大小+1, (获取指定列小数点右侧的数字个数.))) |
| FLOAT FLOAT UNSIGNED | FLOAT |
| DOUBLE DOUBLE UNSIGNED | DOUBLE |
| CHAR VARCHAR TINYTEXT MEDIUMTEXT TEXT LONGTEXT JSON | STRING |
| DATE | DATE |
| TIME | TIME |
| DATETIME TIMESTAMP | TIMESTAMP |
| TINYBLOB MEDIUMBLOB BLOB LONGBLOB BINARY VARBINAR BIT(n) | BYTES |
| GEOMETRY UNKNOWN | 尚未支持 |
数据源选项
| 名称 | 类型 | 是否必须 | 默认值 | 描述 |
|---|---|---|---|---|
| url | String | 是 | - | JDBC连接的URL。示例: jdbc:mysql://localhost:3306:3306/test |
| driver | String | 是 | - | 用于连接远程数据源的jdbc类名, 如果使用MySQL,值为 com.mysql.cj.jdbc.Driver。 |
| user | String | 否 | - | 连接实例的用户名 |
| password | String | 否 | - | 连接实例的密码 |
| query | String | 是 | - | 查询语句 |
| connection_check_timeout_sec | Int | 否 | 30 | 等待用于验证连接的数据库操作完成的时间(秒) |
| partition_column | String | 否 | - | 用于并行处理的分区列,仅支持数字类型主键,且只能配置一个列。 |
| partition_lower_bound | BigDecimal | 否 | - | 扫描的分区列最小值,如果未设置,SeaTunnel将查询数据库获取最小值。 |
| partition_upper_bound | BigDecimal | 否 | - | 扫描的分区列最大值,如果未设置,SeaTunnel将查询数据库获取最大值。 |
| partition_num | Int | 否 | 任务并行度 | 分区数,仅支持正整数,默认值为任务并行度。 |
| fetch_size | Int | 否 | 0 | 对于返回大量对象的查询,您可以配置查询中使用的行取回大小以通过减少满足选择条件所需的数据库访问次数来提高性能。 零表示使用jdbc默认值。 |
| properties | Map | 否 | - | 额外的连接配置参数,当properties和URL有相同的参数时,具体优先权由驱动实现决定。例如,在MySQL中,properties优先于URL。 |
| table_path | Int | 否 | 0 | 表的完整路径,您可以使用这个配置替代query。例如:mysql: "testdb.table1" oracle: "test_schema.table1" sqlserver: "testdb.test_schema.table1" postgresql: "testdb.test_schema.table1" |
| table_list | Array | 否 | 0 | 要读取的表列表,您可以使用这个配置替代table_path示例:[{ table_path = "testdb.table1"}, {table_path = "testdb.table2", query = "select * id, name from testdb.table2"}] |
| where_condition | String | 否 | - | 所有表/查询的通用行过滤条件,必须以where开始。例如where id > 100 |
| split.size | Int | 否 | 8096 | 表的分割大小(行数),读取表时会将表分割成多个分片。 |
| split.even-distribution.factor.lower-bound | Double | 否 | 0.05 | 分块键分布因子的下界。此因子用于确定表数据是否均匀分布。如果计算出的分布因子大于或等于此下界,则表块将被优化以均匀分布。否则,如果分布因子较小,则表将被视为分布不均,如果估计的分片数超过sample-sharding.threshold指定的值,则会使用基于抽样的分片策略。默认值为0.05。 |
| split.even-distribution.factor.upper-bound | Double | 否 | 100 | 分块键分布因子的上界。此因子用于确定表数据是否均匀分布。如果计算出的分布因子小于或等于此上界,则表块将被优化以均匀分布。否则,如果分布因子较大,则表将被视为分布不均,并且如果估计的分片数超过sample-sharding.threshold指定的值,则会使用基于抽样的分片策略。默认值为100.0。 |
| split.sample-sharding.threshold | Int | 否 | 10000 | 此配置指定触发基于抽样的分片策略的估计分片数阈值。当分布因子超出chunk-key.even-distribution.factor.upper-bound和chunk-key.even-distribution.factor.lower-bound指定的范围,并且估计的分片数(计算为近似行数/块大小)超过此阈值时,将使用基于抽样的分片策略。这可以帮助更有效地处理大型数据集。默认值为1000个分片。 |
| split.inverse-sampling.rate | Int | 否 | 1000 | 在基于抽样的分片策略中使用的抽样率的倒数。例如,如果此值设置为1000,意味着在抽样过程中应用了1/1000的抽样率。此选项提供了控制抽样粒度的灵活性,从而影响最终分片数。在处理非常大的数据集时尤其有用,此时可能更倾向于较低的抽样率。默认值为1000。 |
| common-options | 否 | - | 数据源插件通用参数,请参阅Source Common Options了解详情。 |
并行读取器
JDBC源连接器支持从表中并行读取数据。SeaTunnel将使用某些规则来分割表中的数据,这些数据将交给读取器进行读取。读取器的数量由parallelism选项决定。
分割键规则:
- 如果
partition_column不为null,将使用它来计算分割。该列必须在支持分割的数据类型中。 - 如果
partition_column为null,seatunnel将读取表的架构并获取主键和唯一索引。如果主键和唯一索引中有多于一个列,将使用第一个在支持分割的数据类型中的列来分割数据。例如,表有主键(nn guid, name varchar),因为guid不在支持分割的数据类型中,所以将使用列name来分割数据。
支持分割的数据类型:
- 字符串
- 数字(int, bigint, decimal, ...)
- 日期
与分割相关的选项
split.size
一个分割中的行数,读取表时会将表分割成多个分割。
split.even-distribution.factor.lower-bound
不推荐使用
分块键分布因子的下界。此因子用于确定表数据是否均匀分布。如果计算出的分布因子大于或等于此下界,则表块将被优化以均匀分布。否则,如果分布因子较小,则表将被视为分布不均,并且如果估计的分片数超过sample-sharding.threshold指定的值,则会使用基于抽样的分片策略。默认值为0.05。
split.even-distribution.factor.upper-bound
不推荐使用
分块键分布因子的上界。此因子用于确定表数据是否均匀分布。如果计算出的分布因子小于或等于此上界,则表块将被优化以均匀分布。否则,如果分布因子较大,则表将被视为分布不均,并且如果估计的分片数超过sample-sharding.threshold指定的值,则会使用基于抽样的分片策略。默认值为100.0。
split.sample-sharding.threshold
此配置指定触发基于抽样的分片策略的估计分片数阈值。当分布因子超出chunk-key.even-distribution.factor.upper-bound和chunk-key.even-distribution.factor.lower-bound指定的范围,并且估计的分片数(计算为近似行数/块大小)超过此阈值时,将使用基于抽样的分片策略。这可以帮助更有效地处理大型数据集。默认值为1000个分片。
split.inverse-sampling.rate
在基于抽样的分片策略中使用的抽样率的倒数。例如,如果此值设置为1000,意味着在抽样过程中应用了1/1000的抽样率。此选项提供了控制抽样粒度的灵活性,从而影响最终分片数。在处理非常大的数据集时尤其有用,此时可能更倾向于较低的抽样率。默认值为1000。
partition_column [string]
用于分割数据的列名。
partition_upper_bound [BigDecimal]
扫描的分区列最大值,如果未设置,SeaTunnel将查询数据库获取最大值。
partition_lower_bound [BigDecimal]
扫描的分区列最小值,如果未设置,SeaTunnel将查询数据库获取最小值。
partition_num [int]
不推荐使用,正确的做法是通过
split.size控制分割数
我们需要将其分割成多少分割,只支持正整数。默认值是任务并行度。
小贴士
如果表不能分割(例如,表没有主键或唯一索引,并且未设置
partition_column),它将以单一并发运行。使用
table_path替换query以读取单个表。如果需要读取多个表,请使用table_list。
任务示例
此示例查询测试"数据库"中的type_bin 'table' 16数据,并以单一并行方式查询其所有字段。您还可以指定要查询的字段以最终输出到控制台。
定义运行时环境
env {
parallelism = 4
job.mode = "BATCH"
}
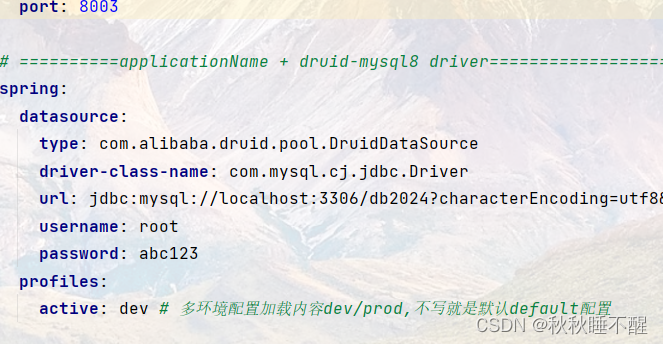
source{
Jdbc {
url = "jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2b8&useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
query = "select * from type_bin limit 16"
}
}
transform {
# 如果您想了解更多关于如何配置seatunnel和查看transform插件完整列表的信息,
# 请访问 https://seatunnel.apache.org/docs/transform-v2/sql
}
sink {
Console {}
}按主键或唯一索引并行
配置
table_path将开启自动分割,您可以配置split.*来调整分割策略
env {
parallelism = 4
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://localhost/test?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
query = "select * from type_bin"
partition_column = "id"
split.size = 10000
# Read start boundary
#partition_lower_bound = ...
# Read end boundary
#partition_upper_bound = ...
}
}
sink {
Console {}
}指定查询边界并行
指定查询数据的上下边界更为高效
env {
parallelism = 4
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://localhost/test?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
table_path = "testdb.table1"
query = "select * from testdb.table1"
split.size = 10000
}
}
sink {
Console {}
}读取多个表
配置table_list将开启自动分割,您可以配置split.*来调整分割策略
env {
job.mode = "BATCH"
parallelism = 4
}
source {
Jdbc {
url = "jdbc:mysql://localhost/test?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
table_list = [
{
table_path = "testdb.table1"
},
{
table_path = "testdb.table2"
# 使用查询文件过滤行和列
query = "select id, name from testdb.table2 where id > 100"
}
]
#where_condition= "where id > 100"
#split.size = 8096
#split.even-distribution.factor.upper-bound = 100
#split.even-distribution.factor.lower-bound = 0.05
#split.sample-sharding.threshold = 1000
#split.inverse-sampling.rate = 1000
}
}
sink {
Console {}
}多表读取
配置table_list将开启自动分割,您可以配置split.*来调整分割策略
env {
job.mode = "BATCH"
parallelism = 4
}
source {
Jdbc {
url = "jdbc:mysql://localhost/test?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
table_list = [
{
table_path = "testdb.table1"
},
{
table_path = "testdb.table2"
# 使用查询文件过滤行和列
query = "select id, name from testdb.table2 where id > 100"
}
]
#where_condition= "where id > 100"
#split.size = 8096
#split.even-distribution.factor.upper-bound = 100
#split.even-distribution.factor.lower-bound = 0.05
#split.sample-sharding.threshold = 1000
#split.inverse-sampling.rate = 1000
}
}
sink {
Console {}
}以上是视频中出现的代码及文档说明,大家可以结合视频中的讲解进行实操,最后如果您对录制感兴趣,请继续往下阅读
如何参与Demo录制?
提交您的Demo
- 准备您的演示:选择一个您熟悉的连接器,准备一个5到10分钟的视频演示。确保视频清晰展示了如何配置和使用该连接器,解决了什么问题,以及可能的最佳实践。
- 提交视频:请添加社区同学微信18819063834上传您的视频和相关描述。
本文由 白鲸开源科技 提供发布支持!